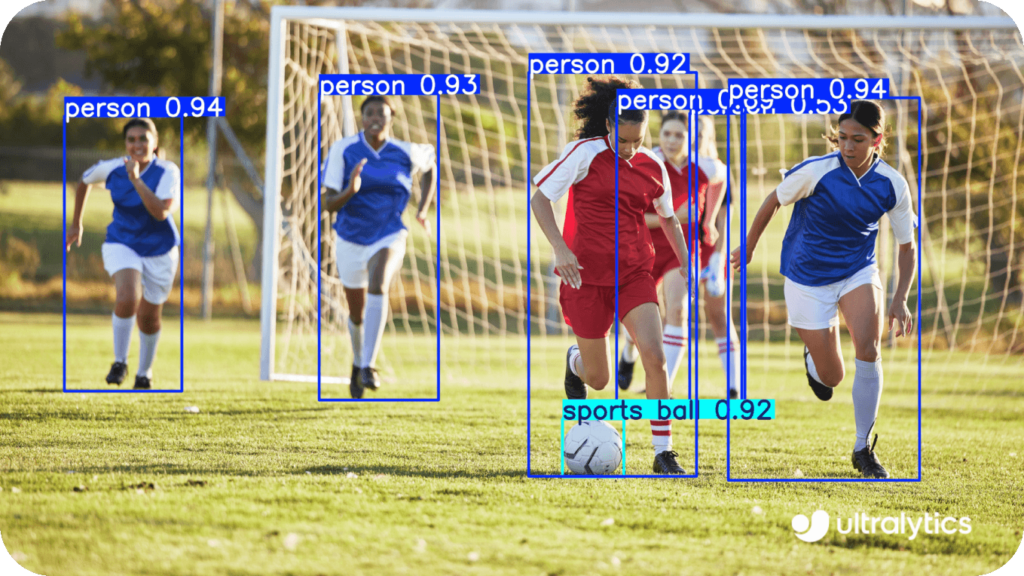
At Zenith Future LLP, we are always at the forefront of technological advancements, and today we want to share some insights about YOLOv11, the latest breakthrough in real-time object detection.
💡 What is YOLO? YOLO, which stands for You Only Look Once, is an object detection algorithm known for its incredible speed and accuracy. It allows systems to detect and classify multiple objects in a single image or video frame almost instantaneously. YOLO’s architecture has evolved over the years, and now YOLOv11 takes this performance to the next level!
🌟 Key Features of YOLOv11:
- Increased Accuracy: YOLOv11 introduces advanced optimization techniques that improve the model’s precision, even with small or overlapping objects.
- Faster Detection: YOLOv11 uses new lightweight architectures, making real-time processing faster than ever before, without compromising accuracy.
- Better Generalization: With better training strategies, YOLOv11 generalizes well to different datasets, making it highly adaptable for a wide range of industries.
- Improved Handling of Low-Light and Adverse Conditions: Enhanced performance in suboptimal conditions like poor lighting, motion blur, or cluttered backgrounds.

🌟 Enhancements in YOLOv11:
- Improved Accuracy Without Sacrificing Speed:
- YOLOv11 introduces a new architecture that increases detection accuracy while maintaining the speed that YOLO is known for. The algorithm incorporates more efficient backbones and better feature extraction techniques, allowing for superior accuracy, especially in complex scenes. The accuracy/speed trade-off has been significantly reduced, making it viable for tasks requiring both real-time processing and high precision.
- Enhanced Small Object Detection:
- YOLOv11 addresses the small object detection issue by introducing multi-scale predictions and better feature pyramids, enabling the model to detect small and far-away objects more accurately. This is crucial for applications like aerial imagery, medical diagnostics, and retail, where small objects are frequent.
- Better Generalization with Fewer Hyperparameters:
- The model in YOLOv11 is designed to generalize better across different domains without the need for extensive hyperparameter tuning. It uses more data augmentation techniques like mosaic augmentation and CutMix, which help improve the model’s robustness on diverse datasets. This makes YOLOv11 more adaptable and ready for different use cases out-of-the-box.
- Handling Complex and Cluttered Scenes:
- YOLOv11 improves detection in scenes with multiple objects and cluttered backgrounds through better feature extraction, helping the model isolate and identify objects even when they are overlapping or partially obscured. This is a significant improvement for sectors like autonomous driving, where complex real-world scenarios need precise object detection.
- Low-Light and Adverse Condition Performance:
- One of the key upgrades in YOLOv11 is its ability to perform well under low-light conditions or in environments with poor visibility. Enhanced training techniques, such as contrastive learning, help the model distinguish objects in adverse conditions like fog, rain, or nighttime.
- Efficient Use of Resources:
- YOLOv11 has been optimized for edge devices and lower-power hardware without significantly compromising performance. This allows industries to use YOLOv11 for real-time detection on IoT devices, smart cameras, or other lightweight systems, making AI more accessible and deployable at the edge.
🛠️ Why YOLOv11 Matters:
YOLOv11 pushes the limits of what’s possible with object detection by combining speed, accuracy, and flexibility. It’s ideal for applications where real-time processing is essential, from smart cities to industry 4.0, autonomous systems, and more.
At Zenith Future LLP, we are continuously integrating this powerful tool to develop AI solutions that help businesses across industries leverage data for smarter, faster, and more reliable decisions.


